

Davide's Code and Architecture Notes - CAP Theorem: it's not just «Pick two»
«Consistency, Availability, and Partition tolerance. Pick two». Is it really THAT simple? Let’s learn a bit more about the CAP theorem.
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer. So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible - I don't want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding.
- Davide
Data consistency is one of the most important things to handle when building distributed systems. Will your users always get the most recent data? Is it really THAT necessary?
In 1998, Eric Brewer came up with the idea of the CAP Theorem: it is often presented with the formula «You have Consistency, Availability, and Partition Tolerance. You can’t have all of them. You have to pick two». Is it really that simple? Are we missing something?
In this article, we will learn about the CAP Theorem in a not-so-shallow way. We will learn what the CAP theorem actually means, what are its limits, and how we can use this theorem to build a system that fits our necessities.
Distributed systems in short
The first thing to define is what is a distributed system.
As you can imagine, we are talking about a system that is distributed. Ok, but how?
When we create distributed systems, we often deploy our systems in multiple nodes distributed across a region, or even worldwide, to give each single node the responsibility to handle a certain amount of load. Having our application distributed on several nodes also helps us in case a node is unavailable: we will not have the whole application down since we can define a strategy to handle this kind of failure.
To help you visualize the idea of a distributed system, look at the diagram below. We have two nodes, Node1 and Node2, and each includes an instance of MyApplication and an instance of the database. Those two instances of the database must be kept in sync, so we have a process (usually implemented by the database vendor) that synchronizes the data between the two instances. Finally, we have one or more clients that communicate with MyApplication, accessing the instance deployed on one of those nodes.
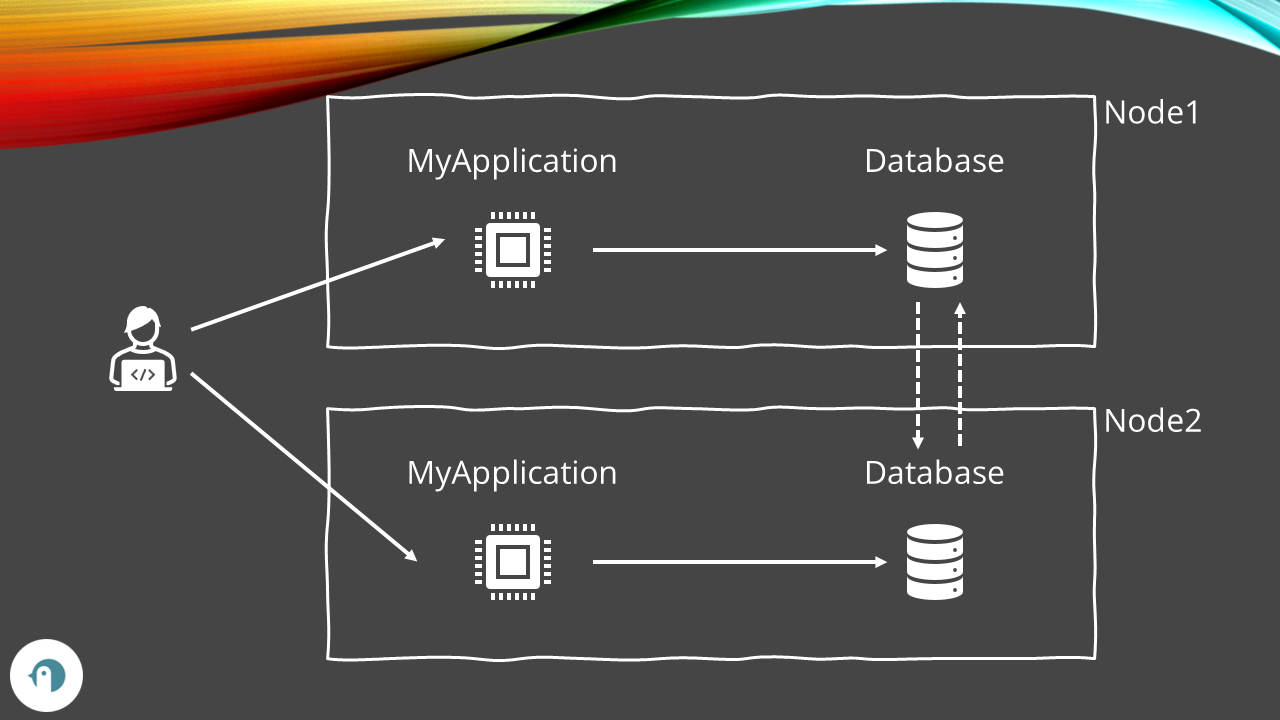
As you can see, the two database instances communicate over the network. Everything would work fine if it wasn’t for a tiny detail: the network is not reliable! A totally reliable network cannot exist (well, given the current technology): packets can be lost, data can be corrupted, and servers can be temporarily unavailable. We must then consider this property of a network when building our distributed systems.
Now that we have defined what a distributed system is, we can move to the actual topic: what do the letters in CAP mean?
Consistency, Availability, Partition tolerance
As you can imagine, CAP is an acronym.
We are going to explain what each letter means in this context.
C: (strong) Consistency
The C in CAP stands for Consistency, meaning that every read either returns the latest data or, in case it is not possible, returns an error. As a matter of fact, this is called Strong Consistency, as opposed to Weak Consistency or Eventual Consistency.
If possible, you will always receive the latest data.
Say that the database stores some data about me. We have
name=Davide
and this value is available both on Node1 and Node2.
Now, a client updates the value by accessing Node2.
name=DavideBellone
A system has the property of being Strongly Consistent if every access to that data always returns the newer value (in this case, DavideBellone) independently from the node that the client accessed.
In case the system cannot guarantee that the result is the most recent data, the system returns an error.
A: Availability
Availability is the property of a system of always responding to a request. In the case of a database, we can define that it has the Availability attribute if a query is always guaranteed to return a value, even if it is not the most recent one.
Let’s use the previous example again. We have two nodes, each of which contains
name=Davide
Now, a client updates the value to DavideBellone.
The system is defined as Available if every query returns a value, regardless of the exact value: it might be the new one (DavideBellone) or the old one (Davide). The important thing is that it always responds.
P: Partition tolerance
Partition tolerance refers to a system that can keep working even in the case of a network error, where some messages are being dropped during the communication between nodes.
When the systems cannot communicate, we talk about network partition failures, meaning that, given that the network cannot guarantee communication between nodes, such nodes are isolated (so, partitioned).
Network failures cannot be avoided. It’s a matter of physical communication, and the only thing we can do is keep this kind of issue in mind and build our systems in a way that such failures can be managed gracefully.
Do we have to «pick two»?
The CAP Theorem is often shortened as «pick two», and in most technical content, you will see the usual triangle where each side represents one of the 3 letters in CAP.
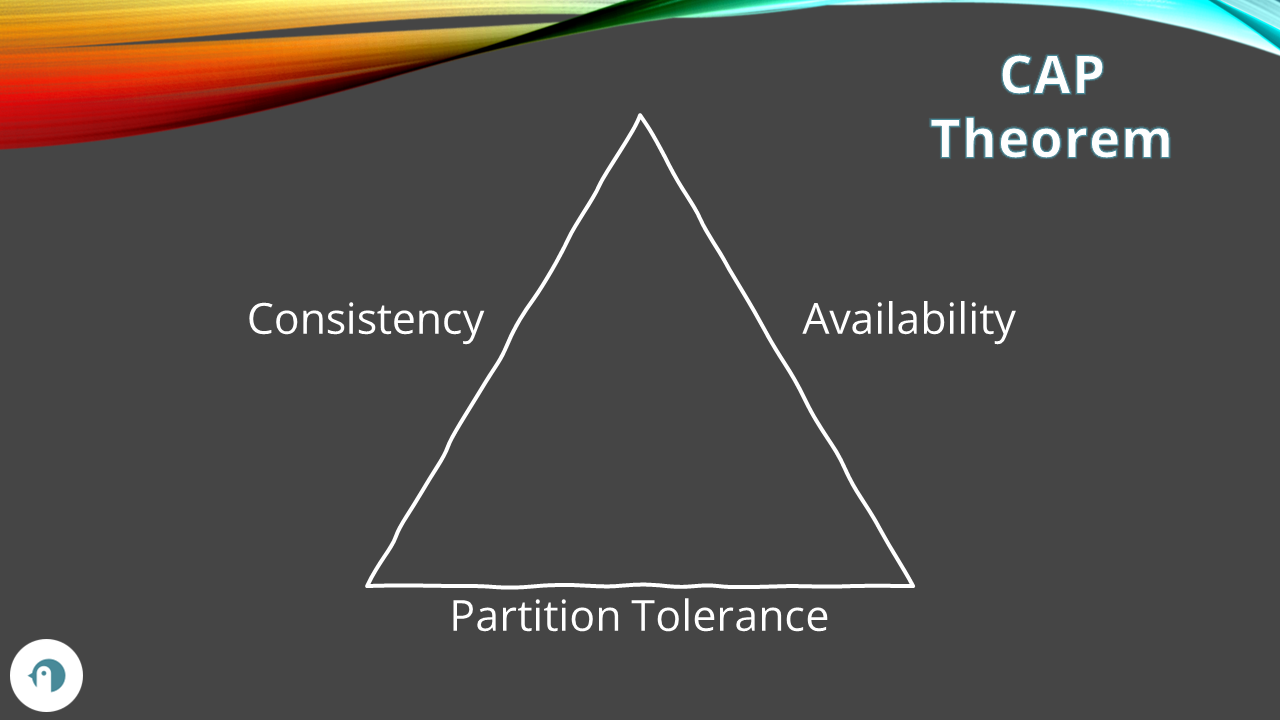
So, you have to pick two sides of the triangle as the most important characteristics, in order to make the best technical choices according to the project needs.
But we already know that network errors will occur!
Let’s get back to the initial example: two nodes whose database instances are kept in sync via the network. Now, imagine that a user writes data on Node1, but for some reason, it is impossible to propagate the change to Node2.
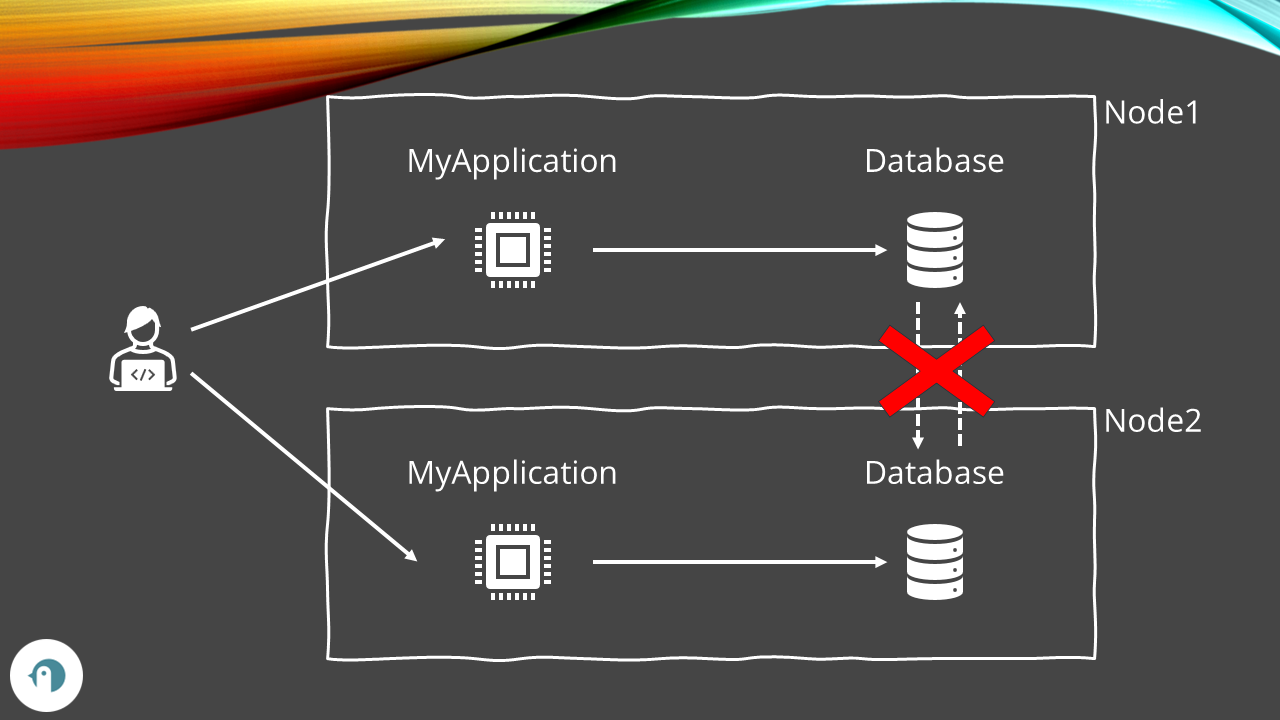
What can we do?
CP: Consistency and Partition tolerance
You can have Consistency and Partition tolerance (CP), sacrificing the Availability.

A system that guarantees CP guarantees that if the system is unable to return the latest data, it will return an error in case of a network error.
Once the network starts working again, the two database instances can communicate again, and the data can be synchronized.
📩 A question for you: a user updates some data on Node1. Due to a network error, the data is not updated on Node2. How can Node2 “know” that some new data has been posted on Node1, and therefore return an error instead of returning the old value, given that Node1 and Node2 cannot communicate because of the network error? 📩
Databases supporting CP generally use the ACID consistency model: a transaction either completes successfully on every node or is rolled back. ACID transactions ensure that data is strongly consistent in all the database nodes.
AP: Availability and Partition tolerance
On the other side, we have AP: Availability and Partition tolerance.
Systems like this sacrifice strong consistency in exchange for availability: sometimes, it’s better to receive not-so-updated data than not receive anything.
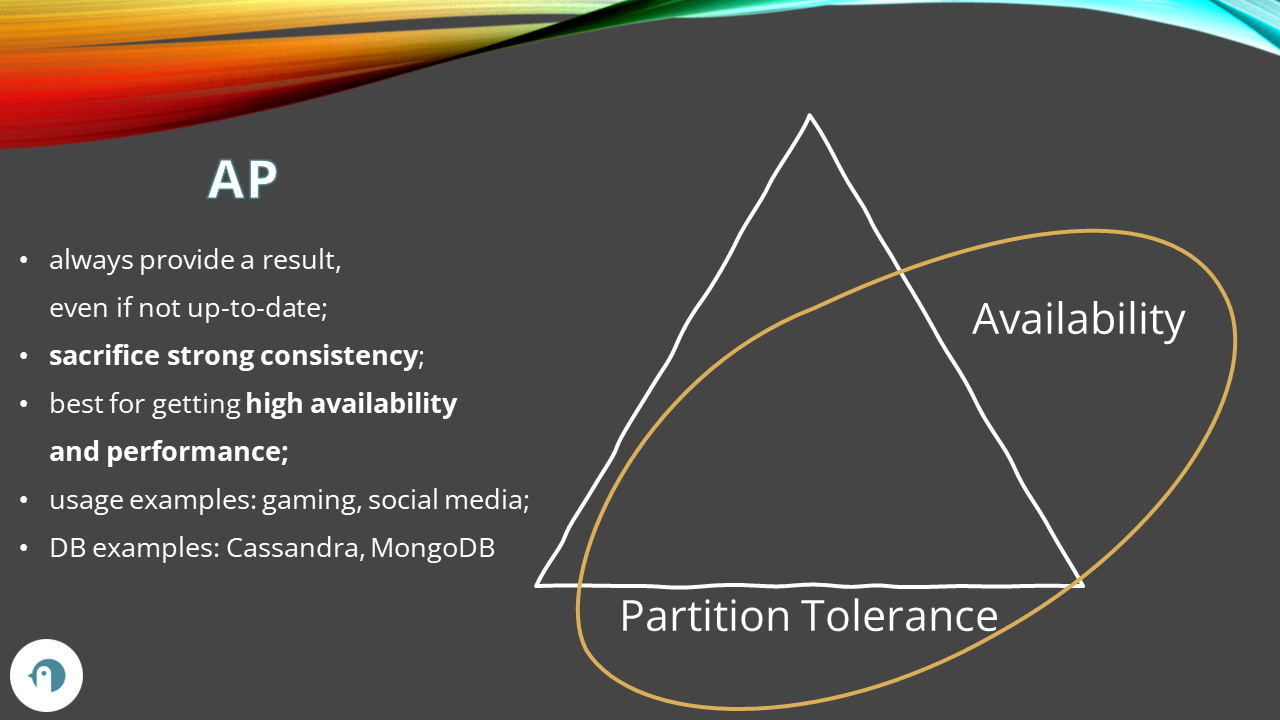
Let’s simulate what happens in an AP system:
- both systems have name=Davide in their database;
- a user updates the value to DavideBellone on Node1;
- the database on Node1 updates the value;
- the network between the two DB instances becomes unavailable: Node2 does not receive the updated value;
- a user accesses Node2 to get the value and receives Davide (the old value)
- the network starts working again; the synchronization can happen;
- Node2 updates its value;
Generally speaking, non-relational databases support the AP mode: using the BASE consistency model (Basically Available, Soft state, Eventually consistency), they can ensure that every query does return a value, even if with the data that does not reflect the latest values.
CA: Consistency and Availability (this cannot exist)
Network errors cannot be avoided. There is no way to create a system that prevents them, so every system will have to deal with network partitioning.
This also means that you cannot have a system that supports Consistency and Availability, but does not support Partition Tolerance: every system, in fact, needs to deal with network partitioning, so the CA combination just cannot exist.
Limits of the CAP theorem
The CAP theorem is pretty famous in the formula «pick two out of three». However, this statement has some limitations:
- it’s not formally correct: you can only pick AP and CP, but never CA;
- in any case, you have consistency; when considering CP, we can have strong consistency, while when considering AP we can have only eventual consistency;
- a system cannot be 100% available; we can try to get high availability, measured with the nines.
- in short, we cannot get a system 100% immediately strongly consistent or 100% available, since there will always be some latency; the choice between Consistency and Availability is not a binary choice, but it’s a spectrum.
So, I came up with this new diagram to explain the CAP theorem:
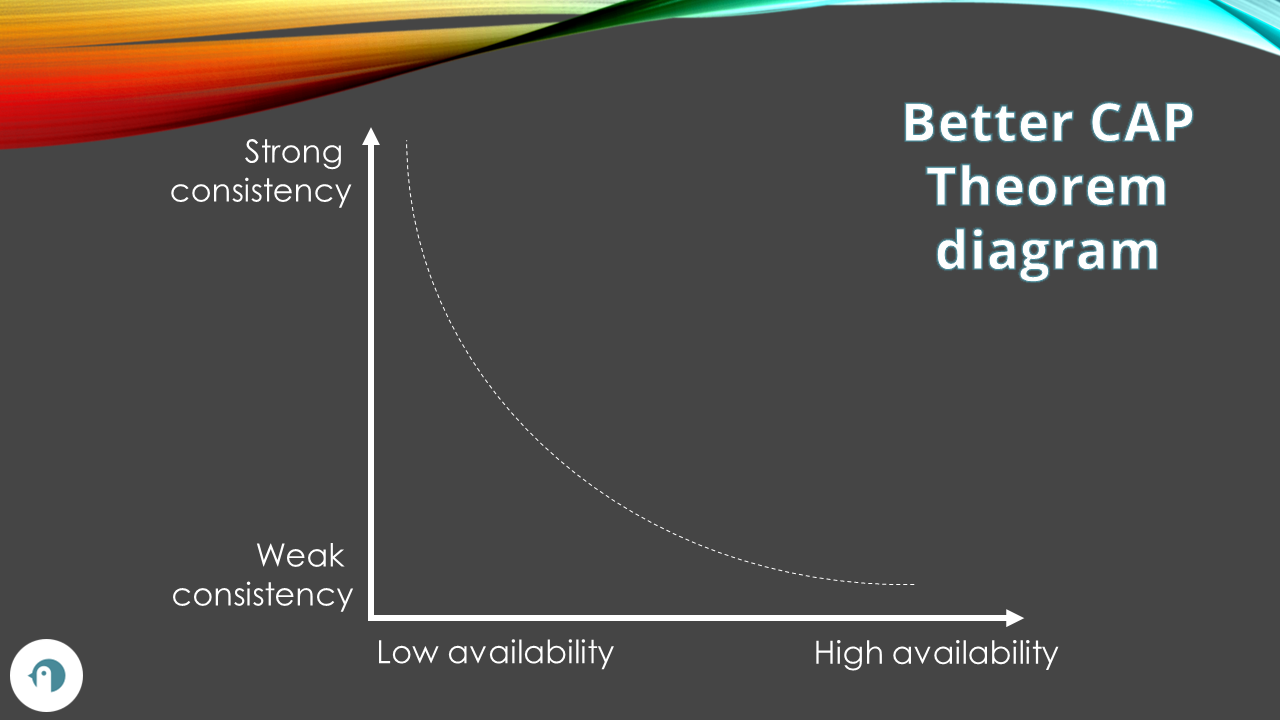
We cannot just «pick two», but we have to decide which levels of Consistency and Availability we need for our system, considering that we will always have network errors.
Further readings
There are a lot of articles out there that talk about the CAP theorem, so here are a few interesting resources.
The first one is this YouTube video by Mark Richards:
🔗 CAP Theorem Illustrated | Mark Richards
Next is the best book on Distributed systems I’ve ever read: “Understanding Distributed Systems” by Roberto Vitillo. In his book, Roberto explains everything you need to know about distributed systems; to better understand the CAP theorem, you need some more theoretical knowledge that I omitted here, but you can find in his book:
🔗 Understanding distributed systems | Roberto Vitillo
This article first appeared on Code4IT 🐧
Finally, since the CAP Theorem does not fully describe the essence of distributed databases since it does not consider latency, you can read about another theorem that builds upon the CAP theorem:
Wrapping up
In this article, we’ve learned about the CAP theorem and why it’s not just «pick two».
As we’ve learned, it’s not just a choice between the 3 edges of the triangle: it’s a matter of choosing what is more important: consistency or availability?
I hope you enjoyed this article! Let's keep in touch on LinkedIn, Twitter or BlueSky! 🤜🤛
Happy coding!
🐧