

Davide's Code and Architecture Notes - 4 algorithms to implement Rate Limiting, with comparison
You should always put a limit to the number of incoming requests. Otherwise, you can have your systems exposed to malicious attackers. Let’s see the four main algorithms to implement Rate Limit.
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer. So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible - I don't want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding.
- Davide
When developing any API application, whether it is a monolith, a microservice, a distributed system, or whatever, you should add some sort of Rate Limiting.
Rate Limiting is just a way to say to the caller, “Hey, stop, you’re calling me too many times!”. At first sight, it’s easy. But… What do we mean by “too many times”? How can we track these “too many times”?
In this article, we will learn what Rate Limiting is and what problems it solves; we will also focus on the four main algorithms to determine if the callers have reached the limit.
What is Rate Limit
Rate Limiting is a way to stop clients from calling our systems too many times.
Considering that every request to our system uses part of our resources, if we have too many requests simultaneously, we could end up with the whole system down. Sure, we could add a L4 or L7 Load Balancer to our system, but it might not be enough.
Adding Rate Limiting has some benefits:
- It shields you from DDoS - if an attacker tries to impact your system by calling your APIs so many times that the whole system goes down, thanks to Rate Limiting, you have a way to reduce the number of performed operations (clearly, you can’t stop the client from calling you, but you can stop before executing the whole operation).
- It adds a security layer preventing Brute force attacks. Let’s see a practical example: if an attacker attempts to steal the identity of a person by trying all the possible passwords (using password spray), your Rate Limit policies stop them from performing too many tentatives.
- If part of the system is degraded and cannot process a request quickly, a client could add a retry policy. Suppose the caller calls you too many times. In that case, it might overload the already degraded component, making it totally unable to handle any request, even coming from other clients.
To ensure the clients know that you are not processing their requests because they tried to call your systems too many times, you have to use the correct HTTP Response code: 429 Too Many Requests. This way, the callers can implement a retry logic that considers that if the call was unsuccessful, it might be due to the number of subsequent calls. The response should also include a Retry-After HTTP header to tell the client how long to wait before performing the next request.
Rate Limiting algorithms
Now, what strategies do we have to implement Rate Limit?
Let’s see the 4 algorithms!
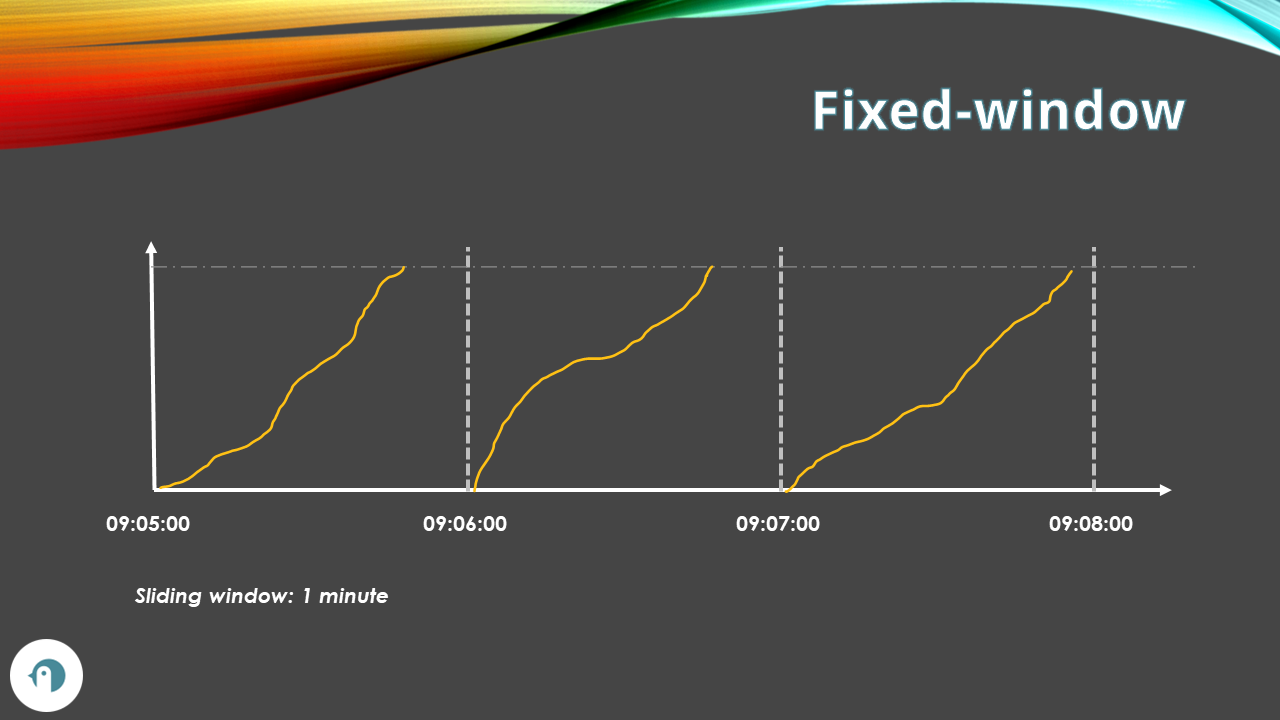
Fixed-window rate limiting
The Fixed-window algorithm restricts the number of requests allowed during a given time window. The time frame is defined by the server, and it’s the same for all the clients.
Say that we define that we can accept 100 requests every minute. Then, after the minute passes, we can accept 100 more.
You can choose two types of fixed-window rate limiting: user-based and server-based. User-based fixed-window rate limiting allows any user to perform, in our example, 100 requests per minute. Server-based fixed-window rate limiting defines that the whole server is capable of processing 100 requests per minute, regardless of the caller.
This algorithm is simple to implement, but it has some drawbacks. One is that it can allow bursts of requests at the beginning or at the end of each window, which can overload the system. Also, suppose a lot of requests are throttled to the next minute. In that case, you end up adding and adding more requests to the beginning of the next minute, causing a burst of requests that the system might not be able to handle.
Sliding-window Rate Limiting
The Sliding-window algorithm divides the time into fixed intervals, such as seconds or minutes, and each interval starts with the first request of the client.
If the timeframe is 100 requests per minute, we can have:
- ClientA, that makes the first request at 09:00:05, can call the system 100 times until 09:01:05.
- ClientB, that makes the first request at 09:00:38, can call the system 100 times until 09:01:38.
So, both clients can call the system 100 times per minute, but their time frames are independent of each other. Timeframes can overlap.
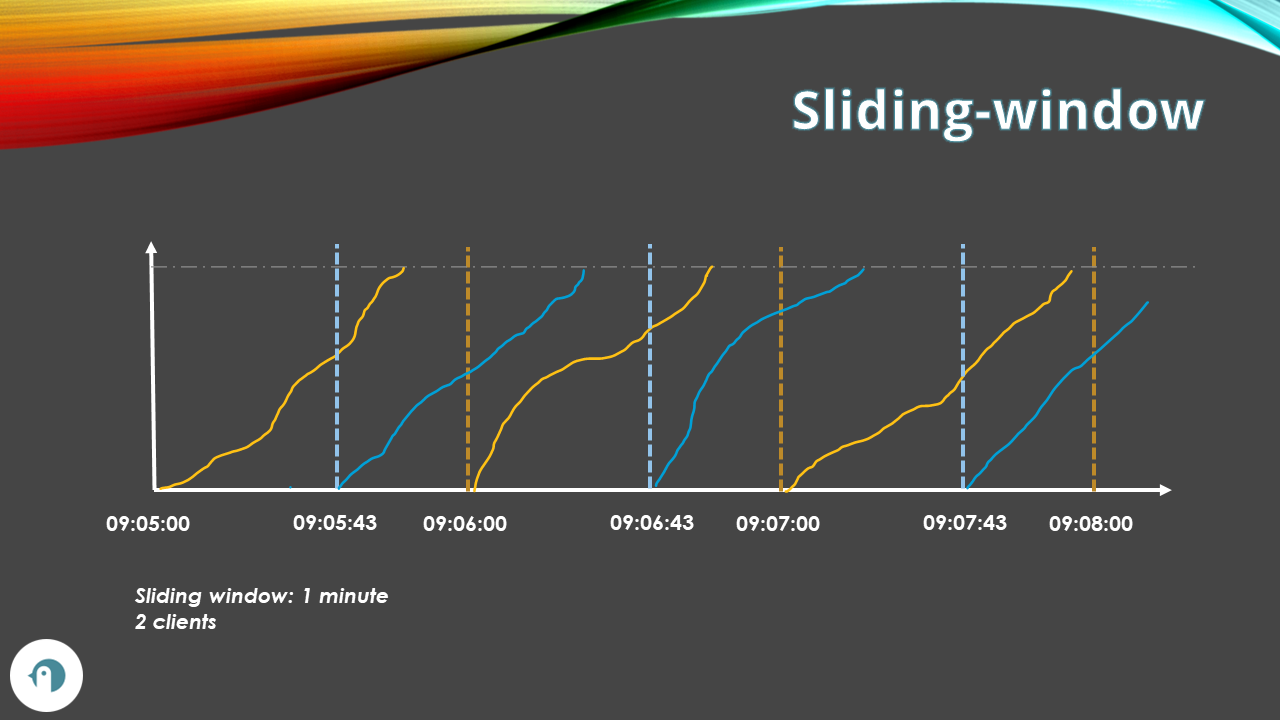
This algorithm is more fair than the fixed-window algorithm, as it considers the request history of each independent client in a sliding window rather than a fixed window.
However, given that you must now store info about the request counters related to each client, it is also more complex and resource-intensive to implement.
Leaky Bucket rate limiting
The Leaky bucket algorithm simulates a leaky bucket that can hold a fixed number of requests.
Picture a bucket with a tiny hole at its base. The bucket is filled with water (symbolizing incoming requests) at varying speeds, but the water leaks from the hole steadily. If the bucket is already full and additional water is added, it spills over, representing the discarding of extra requests.
This algorithm ensures the request flow is constant and mitigates congestion. If requests are added faster than they can be processed, the surplus requests are discarded.
The algorithm can be implemented using a FIFO (First In, First Out) queue. The queue stores the list of requests, and a fixed quantity of requests are removed from the queue at a regular pace, and then processed.
Let’s see a practical example: each request fills one slot (a drop of water) in the bucket, and each slot leaks out constantly. If the bucket size is 100 requests and the leak rate is 5 requests per second, then if every client sends more than 5 requests per second, the bucket will fill up, and incoming requests will be blocked or throttled until some slots leak out.

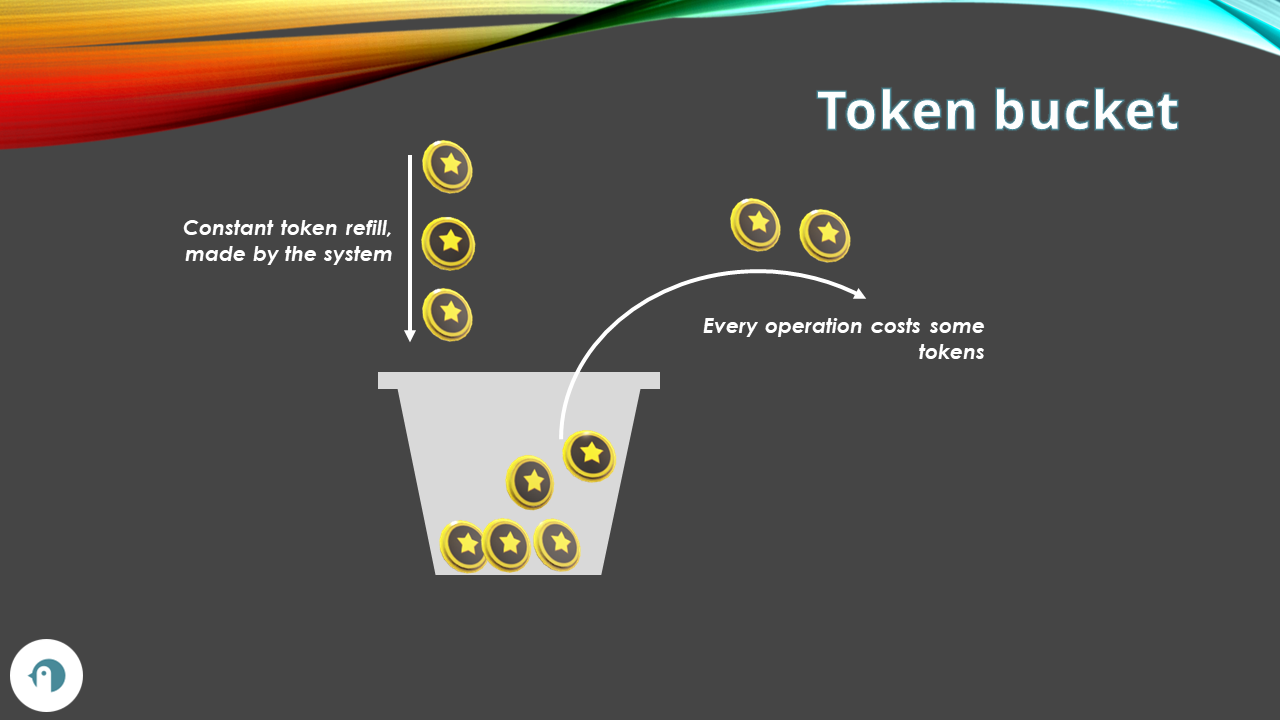
Token Bucket rate limiting
The Token bucket algorithm is similar to the leaky bucket algorithm, but instead of filling slots with requests, it consumes tokens from a bucket.
Each client has an allocated number of tokens it can consume. It can use them all in a burst, or use them at a regular pace.
The bucket now has a minimum (zero) and a maximum number of tokens available. When a request arrives, the system removes the related number of tokens from the bucket.
At the same time, tokens are added at a constant rate. For example, in a bucket with at most 100 tokens, the system can add 5 tokens every 10 seconds. Once the bucket has reached the limit, the system drops the exceeding tokens (and not the requests).
One of the differences with Leaky Bucket is that Token Bucket allows bursts of requests, while Leaky Bucket only supports requests to be processed at a constant rate.
Comparing the Rate Limiting algorithms
Let’s compare the main differences of the four algorithms.
| Algorithm | Description | Burst Handling | Discarding | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Fixed Window | Divides time into fixed windows. For each window, it maintains a counter of requests. When the counter reaches the limit, subsequent requests are dropped until a new window starts. | Does not handle bursts. | Discards requests when the limit is reached. | Easy to implement. It can prevent the starvation of newer requests. | Can lead to a rush in requests, especially at the beginning of the time window. |
| Sliding Window | Uses a moving window to track the number of requests made over a given time period. The window is strictly related to the caller, and not shared with other clients. | Handles bursts by taking the previous counter into account. | Discards requests when the estimated count is greater than the capacity. | Handles bursts by taking the previous counter into account. More accurate than Fixed Window. | More complex to implement than Fixed Window. |
| Leaky Bucket | As a request arrives, it is leaked out of the bucket at a constant rate. If the bucket is full when a request arrives, the request is discarded. | Does not handle bursts. Sends requests at an average rate. | Discards requests when the bucket is full. | Sends requests at a constant rate. More robust compared to Token Bucket. Memory efficient. | Can lead to request loss since it discards requests (not tokens). Processes requests at an average rate, leading to a slower response time. |
| Token Bucket | A token is added to the bucket every N seconds. The bucket has a maximum number of tokens it can hold. If a token arrives when the bucket is full, it is discarded. | Allows for large bursts to be sent faster. | Discards tokens, but not requests. | Allows for large bursts to be sent faster. Tokens are discarded, not requests. Memory efficient. | Might exceed the rate limit during the same time window. Inefficient use of available network resources. |
Further readings
There is a lot more to know about Rate Limit and its different algorithms.
One of the best articles out there has been published by TIBCO:
🔗 What is Rate Limiting? | TIBCO
This article first appeared on Code4IT 🐧
If you want to know more about the Leaky Bucket algorithm, here’s a fantastic article with clear examples and some code snippets in C++, Java, C#, and more. It actually talks about packets (Leaky Token is also used in networking), but the idea is the same:
🔗 Leaky bucket algorithm | GeeksForGeeks
Finally, in 2022 Microsoft announced that they added Rate Limiting capabilities in .NET 7, available under the System.Threading.RateLimiting namespace:
🔗 Announcing Rate Limiting for .NET| DotNET blog
Wrapping up
This article just scratched the surface of the four main algorithms for rate limit.
Each of them is way more complex than I described. Also, because here I simplified everything considering a single node - things change a lot when dealing with distributed systems.
However, learning that these algorithms exist and that they solve different problems can help you pick the right one for your applications.
I hope you enjoyed this article! Let's keep in touch on LinkedIn, Twitter or BlueSky! 🤜🤛
Happy coding!
🐧