

14 to 2 seconds: how I improved the performance of an endpoint by 82% - part 1
Having fast API response is crucial for your applications. In this article you’ll see how I managed to improve an API application that took 14 secs each call.
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer. So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible - I don't want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding.
- Davide
A few weeks ago I was tasked to improve the performance of an API project that was really, really slow.
After more than 3 weeks of work, I managed to improve performance: the initial 14 seconds became less than 3 seconds! Not enough, I know, but still a great result!
So here’s a recap of this journey. I will list some of the steps that brought me to that result and that maybe can help you.
I will not give you any silver bullet to achieve this result - there aren’t any. I’m just going to list some of the steps that helped me figuring out how to improve the overall performance and be sure to do it in the best way.
Since there’s so much to learn, I’ve split this article into 2 parts: in this part, you’ll see some generic tips, not related to a particular technology. In the next article, we’ll see some improvements strictly related to .NET applications.
A short recap for the lazy reader
As I’ve already explained on Twitter, there are some tips that can help you find performance issues. Those tips are not strictly technical; rather they are a general approach to this problem.
- cover your application with e2e and integration tests. You’re going to change the implementation details, so your unit tests will fail.
- use tools to profile performance: you can use advanced tools or create custom stopwatches.
- study the logic before the implementation details. Performance issues usually come from wrong
ifstatements, useless loops, or excessive data retrieval. - Disable cache. An application must be performant regardless of cache mechanisms. Caching is just an additional improvement, but it’s not the solution to performance issues.
- Learn language and platform details. This step is the only one that strictly depends on the language you are using. I’m going to show a few common errors in .NET applications that can slow down your application.
But there is more, of course. If you have more tips to share, feel free to share your experience in the comments.
The original problem
To fully understand how I acted and what issues I came across, I need to explain the general problem and the data flow. Of course, I have to censor the name of the project and the client, so I’ll use generic names.
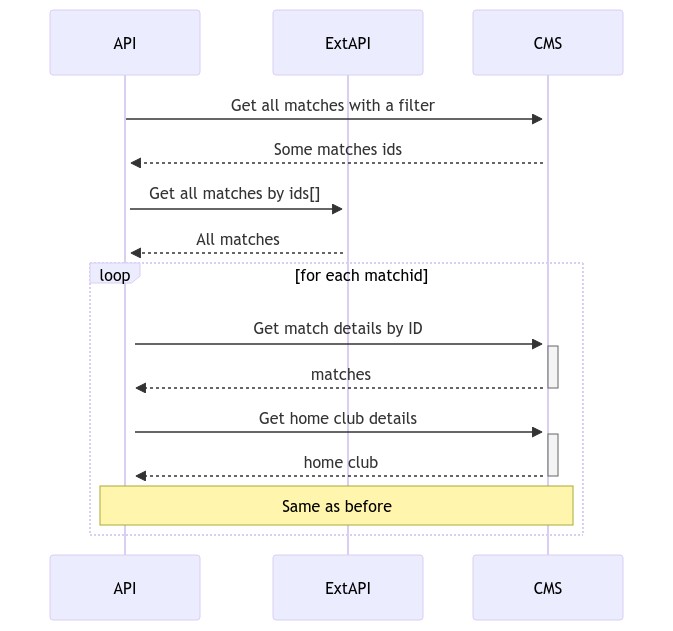
The 14-second endpoint is used to get info about all the matches that were played for a certain sport on a range of dates. The API retrieves data from 3 sources: the internal CMS, an external API, and an assets management platform - like Cloudinary, but created and maintained by my company.
So, when a client calls our API, we perform the following steps:
- Get all the matches from the external API
- Get for each match
- Get match details from the CMS - including the IDs of the clubs that played that match, the venue, and some other info
- Get club details from CMS (both home and away clubs)
- Get venue details from CMS
- Get assets info for the clubs
- Get assets info for the venue
- Get assets info for the other fields
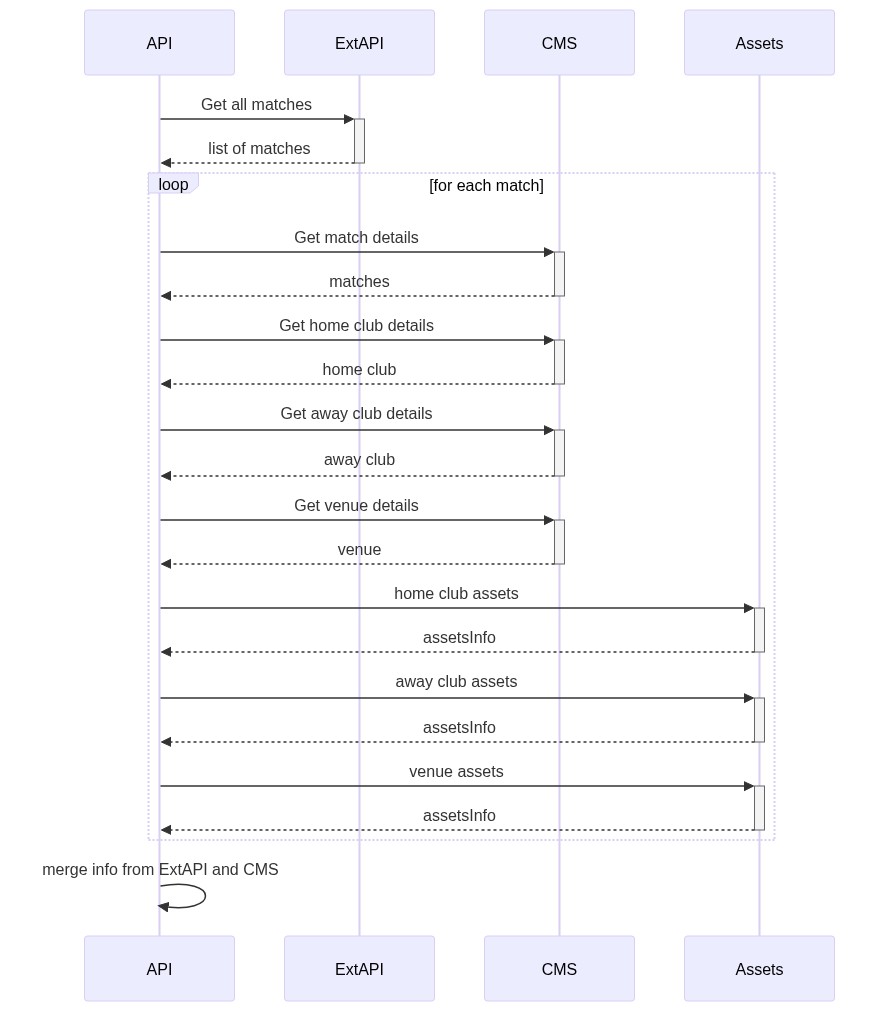
As you can see, there are lots of sequential calls to compose just one object.
Another problem: the whole project was a mess. Not a single test, a huge amount of technical debt; it was a managers’ choice: they needed to integrate the API as soon as possible, without worrying about maintainability, performance, and so on. In my opinion, not the best choice; but if they took this decision, they surely had a reason to choose this path.: I trust my team and the management: they generally crave good quality software.
So, how did I approach the problem?
Create end-to-end tests
Probably you’re going to change a lot of stuff in your code. So, your unit tests will fail. And even if you fix the tests, it doesn’t provide any value in this step. You want to get the same results as before, but in a faster way.
It’s useless - even dangerous - to mock all the dependencies just to keep the unit tests passing. In this phase, you have to focus on avoiding regressions on your code. If a field is populated with a certain value, you need to ensure that, at the end of the refactoring, you receive the same, exact result.
I created an E2E project with one purpose: call the actual API, read the result, and then compare the result with the one I stored in a JSON file.
So, the first step: create Manifest files with the JSON result coming from the dev environment. You can see how to create and use Manifest files in .NET in this article.
Once I have some of the possible results stored in JSON files, I read them and compare the actual call result to the original one. No changes -> no regression.
To run the test I set up an In-memory Server as I explained in this article. So, a sample test has this shape:
[Test]
public async Task Matches_WithDates()
{
// read from Manifest File
var fakeMatchesWithDates = await GetFakeMatchesWithDates();
// call the actual URL on my In-memory server
HttpResponseMessage httpResponse = await client.GetAsync($"/api/matches?culture=en-us&dateFrom=2020-11-01&dateTo=2021-03-01");
// read and parse the result
var actualResult = await TestUtils.DeserializeHttpResponseContent<List<Match>>(httpResponse);
// check the content
actualResult.Should().BeEquivalentTo(fakeMatchesWithDates);
}
You should write a test for each endpoint you’re going to update.
But this approach has a downside that made me delete every test! In fact, as I explained before, one of the parts to be integrated was the internal CMS. But, since other colleagues were working on the same set of data, I needed to update the JSON files every time they modified one of the entities.
The result? Lots of time spent updating the JSON.
So, I can propose 2 possible solutions:
- write loose tests. Don’t test for the exact value of each field, but check if the general structure is the same (the result has the same items count, the field names are the same, and so on)
- use a sandboxed environment: create a clone of a real environment, import some content, and run tests on that new environment.
Use profiling tools
You must not assume that a certain operation is the application bottleneck. You have to prove it.
So, use tools to keep track of the progress. To track performance in .NET you can use the dear old System.Diagnostics.Stopwatch class: you create a StopWatch, make it start, execute the code and then stop it; then, you print/store the result.
void Main()
{
Stopwatch sw = new Stopwatch();
sw.Start();
var x = LooongOperation();
sw.Stop();
Console.WriteLine("Time (ms): " + sw.ElapsedMilliseconds);
}
int LooongOperation() {
Thread.Sleep(1250);
return 42;
}
If you want something more complex, you can use external tools for .NET like MiniProfiler and Rin: with these tools, you define the portion of code to be profiled and, instead of saving manually the results, you analyze the results in the UI provided by the tool itself.
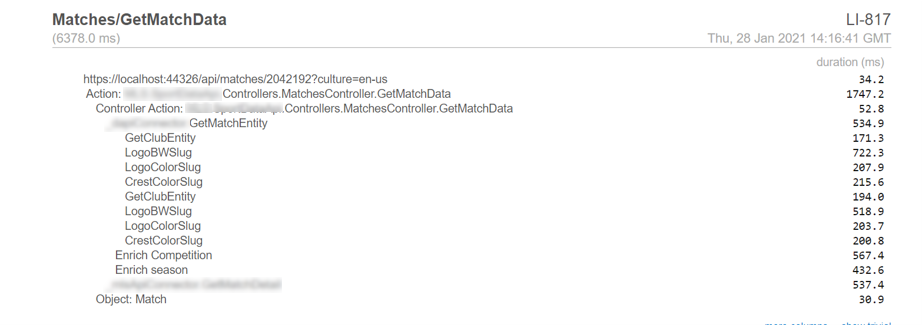
With MiniProfiler the results are displayed in a simple, textual format:
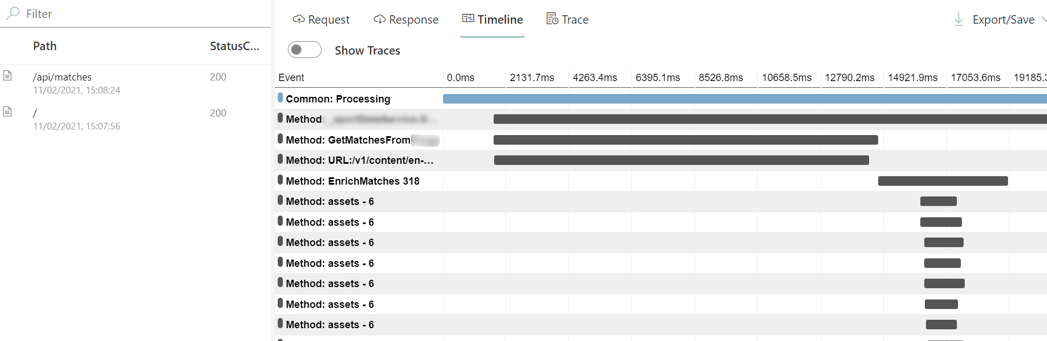
With Rin, you see them with a more complex UI with a timeline:
Rin and Miniprofiler must be added in the Startup class, so their best usage is in .NET MVC/API applications and Azure Functions (yes, you can use the Startup class even for Azure Functions!)
So, how do you collect tracing data with Miniprofiler and Rin?
In both cases, you wrap the code in a using block. With MiniProfiler you use this way:
using (MiniProfiler.Current.Step("Performing loong operation"))
{
var x = LooongOperation();
}
while in Rin you use this other.
using (TimelineScope.Create("Performing loong operation"))
{
var x = LooongOperation();
}
So, now, run the code, watch the performance traces and store them somewhere (I stored the screenshots in a Word file).
Refactor, refactor, refactor
As I said, the code was a total mess. Duplicated methods, repeated business logic, enormous classes…
So, the only thing that can save you is a long, focused day of pure refactoring.
You need to come up with a code that can be easily manipulated and updated: use generics, abstract classes, refactor the modules, and clean up the code.
This part has 3 main advantages, in our specific case:
- you (almost) fully understand how the code works
- you can improve the single steps without the worry of breaking other code
- you can add the profiling steps (Rin, MiniProfiler, or similar) in your code without adding too much mess
So, take a whole day to refactor the project.
Disable cache
Your application must be performant even without cache mechanisms. So, disable it!
Yes, you should access remote resources placed under an external cache (like sites under Akamai). But your application should not use local cache - in this phase.
The cache must improve an already performant application: don’t rely on it to find performance issues.
Yes, if you cache everything, you’ll surely have great results (I went from 14 seconds to 40 milliseconds). But once the cache expires or the application is restarted, you’ll going to face the same problem over and over again.
Understand and update the logic of the application
Once you have the code clean enough to understand the data flow, and you have tools that show you the timings, find the bottleneck.
In my case, I had 2 main bottlenecks: the access to the ExtAPI and the retrieval of assets info.
So, I found two ways to improve the business logic.
Reduce calls to the ExtAPI
First of all, I narrowed down the items to be retrieved from the ExtAPI. To do so, I added one more call to the CMS to get only the items that matched a certain filter.
Then, I used only the returned ids to get data from ExtAPI and CMS.
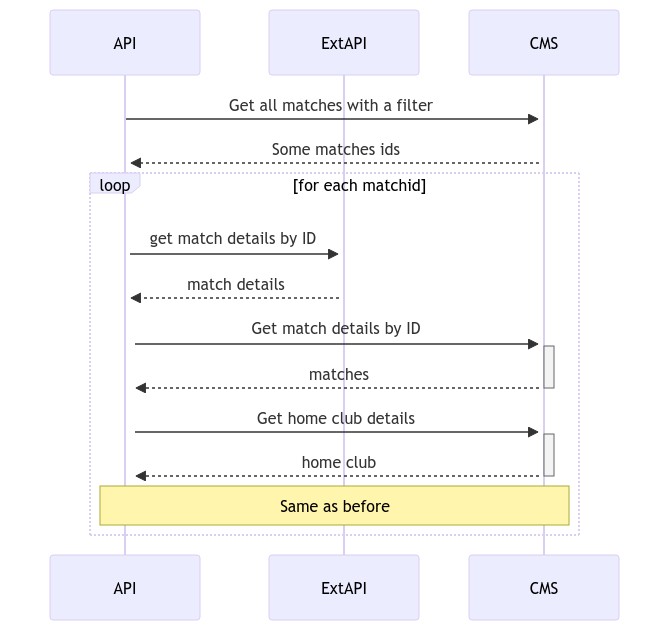
Then, I studied better the ExtAPI endpoints and found out that we could perform a single call to get details for every match passed in query string: just this single trick improved a lot the performance: instead of N API calls, I performed a single API call for N items.
Reduce calls to Assets
Similarly, I optimized the access to the Assets endpoint.
Instead of performing a call for every item I needed (so, venue images + home club images + away club images, one for each match), I performed a single call for every match with all the images I needed.
So, I transformed this:
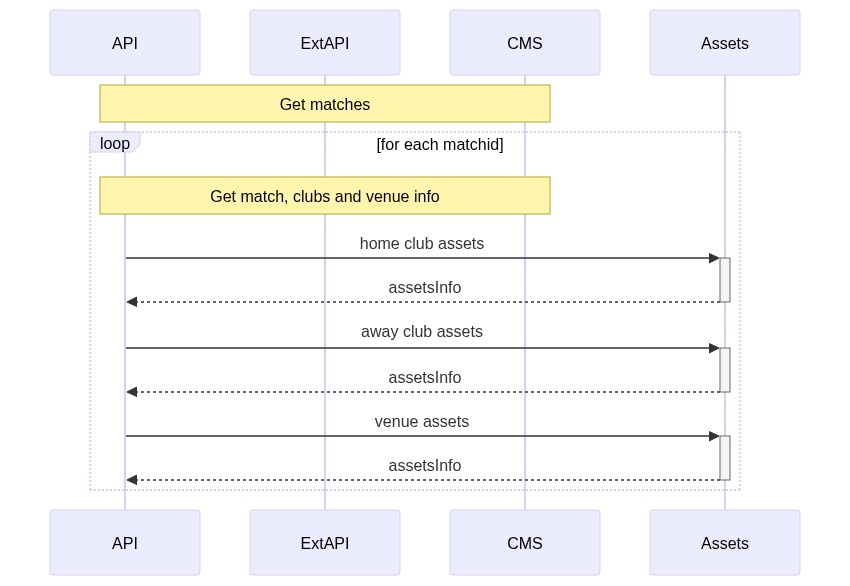
Into this:
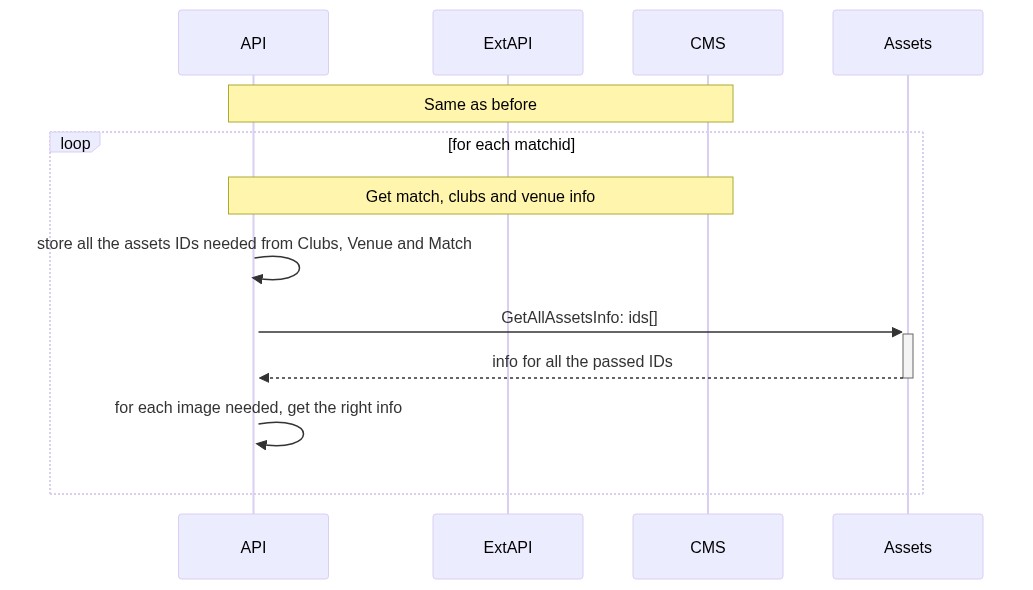
What do I mean by “for each image needed, get the right info”?
I stored all the info coming from the Assets on a Dictionary<string, ImageInfo>.
This allowed me to get the correct info in this way:
string[] ids = GetRequiredImagesIds(match);
Dictionary<string, ImageInfo> infoDictionary = assetsWrapper.GetImages(ids);
// other stuff
match.Venue.MainImage = infoDictionary[match.Venue.MainImageId];
match.HomeClub.MainImage = infoDictionary[match.HomeClub.MainImageId];
// and so on...
Of course, the GetRequiredImagesIds method analyses the input match and returns all the image ids that need to be retrieved.
Again, just changing the order of the operations and optimizing the external calls, I minimized the number of remote calls, thus reducing the general timing.
Study well and deeply your external dependencies
As I already stated, I found out that the Assets API allowed executing a query for a list of values at the same time: this simple discovery boosted the performance of the application.
So, my suggestion is: study and experiment with the external APIs you are working with. Maybe you’ll find an endpoint or a flag that allows you to reach better performance in terms of calculation and data transportation.
Look if you can:
- get multiple items by passing multiple IDs: if you have an endpoint like
/matches?id=123, you can search for something like/matches?id=123,456or/matches?id=123&id=456. Maybe it does not exist, but just in case… - reduce the number of fields to be returned: sometimes you can ask for the exact fields you need, like in OData and in GraphQL endpoints; so, instead of return a whole, complex object when you just need a name, just ask for that single field.
- apply strict filters on search from remote endpoints: instead of getting 1000 items from the APIs, fetching them to exclude the ones that do not match your requirements, thus getting only 30 items, push the filtering on the API side. If you’re interested in the result of a club’s matches, filter all the matches played by that club and already played: you are not interested in a match not played yet, are you?
Remember that not always the documentation is well written and with all the options: so try and experiment by yourself
Wrapping up
In this first part, we’ve seen general concepts to approach the performance analysis of an application. As you have seen, there is almost nothing related to the .NET world, even though all the examples are written having .NET in mind; by the way, those general rules can be applied to every language and platform.
In the next article, we’re going to see something more related to .NET and C#.
Happy coding!